Como descargar todos los documentos PDF del Registro Público de Concesiones del IFT.
 mario.hernandez
28 November 2019
mario.hernandez
28 November 2019
En el Registro Público de Concesiones (RPC) en donde podrás consultar la información de las CONCESIONES, PERMISOS Y AUTORIZACIONES que en materia de telecomunicaciones y radiodifusión han sido otorgadas, con la facilidad de visualizar la información (folio electrónico, fecha de otorgamiento, vigencia, cobertura, servicios, modificaciones, etc.) y descargar los documentos en formato PDF.
Si bien en el RPC viene toda la documentación organizada y actualizada, existirán aplicaciones donde se requiera contar con toda la documentación en PDF en nuestros equipos, tales como:
- Consulta de documentos Offline;
- Análisis e identificación inteligente de texto en los PDFs;
- Organizar la documentación de otra manera;
- Revisar la integridad de los links a los PDFs (Links rotos).
En el presente post se descargarán todos los documento PDF asociados a un determinado Folio electrónico, como ejemplo, utilizaremos la infraestructura de radiodifusión de televisión digital terrestre, el cual podrás encontrar en el siguiente link http://ucsweb.ift.org.mx/vrpc/visor/downloads. Es un archivo de excel en la sección "Infraestructura de estaciones de TV". Para realizar la descarga del archivo desde python3 lo realizamos con:
import wget
infra_TDT_nombre = 'InfraestructuraEstacionesRadio_TV_19112019.xlsx'
infra_TDT = f'http://ucsweb.ift.org.mx/vrpc/assets/publish/infraestructura/{infra_TDT_nombre}'
wget.download(infra_TDT)
print('\nArchivo descargado')
Una vez descargado el archivo, lo que necesitamos conocer es el "Folio electrónico" asignado a cada registro:
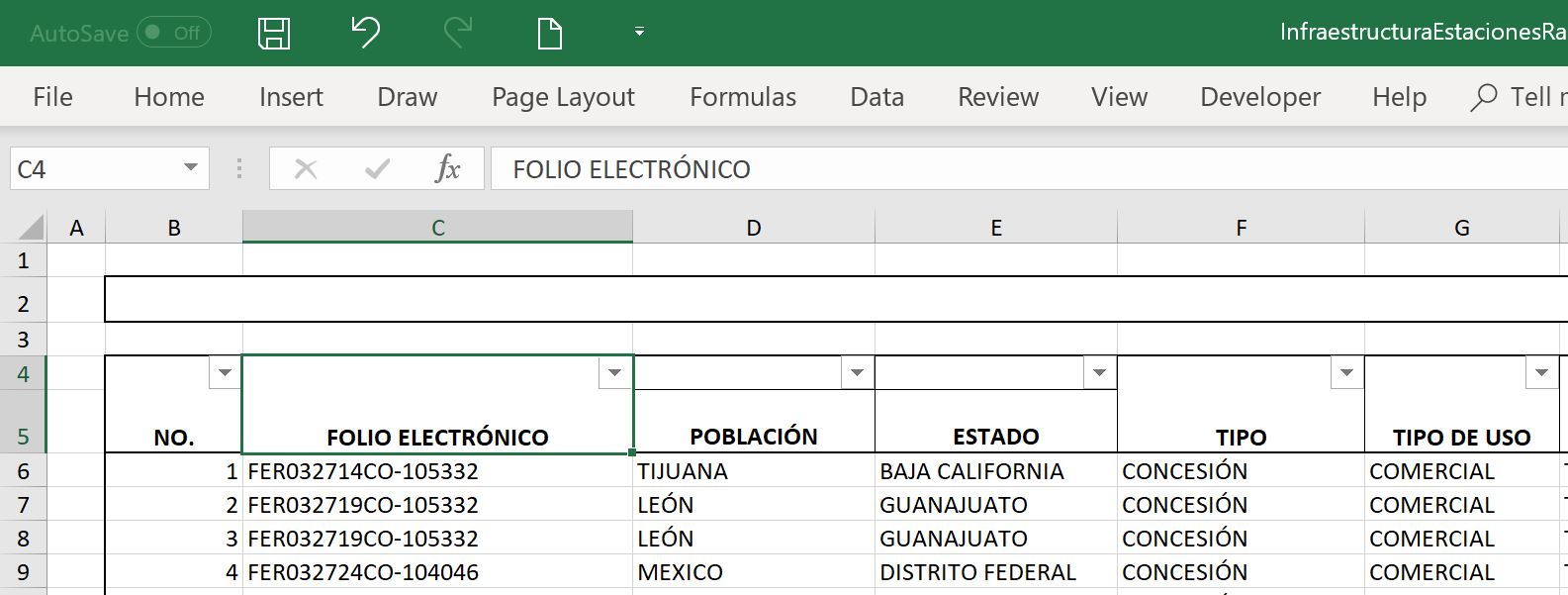
Así por ejemplo si queremos ingresar al folio electrónico del registro numero 1 y 4, sería con los links:
- http://ucsweb.ift.org.mx/vrpc/RpcSearchController/showConcesionInfo?idConcesion=FER032714CO-105332
- http://ucsweb.ift.org.mx/vrpc/RpcSearchController/showConcesionInfo?idConcesion=FER032724CO-104046
Conociendo lo anterior, podemos realizar un script que ingrese a esas direcciones y descargue los los documentos PDFs de la sección Documentos:
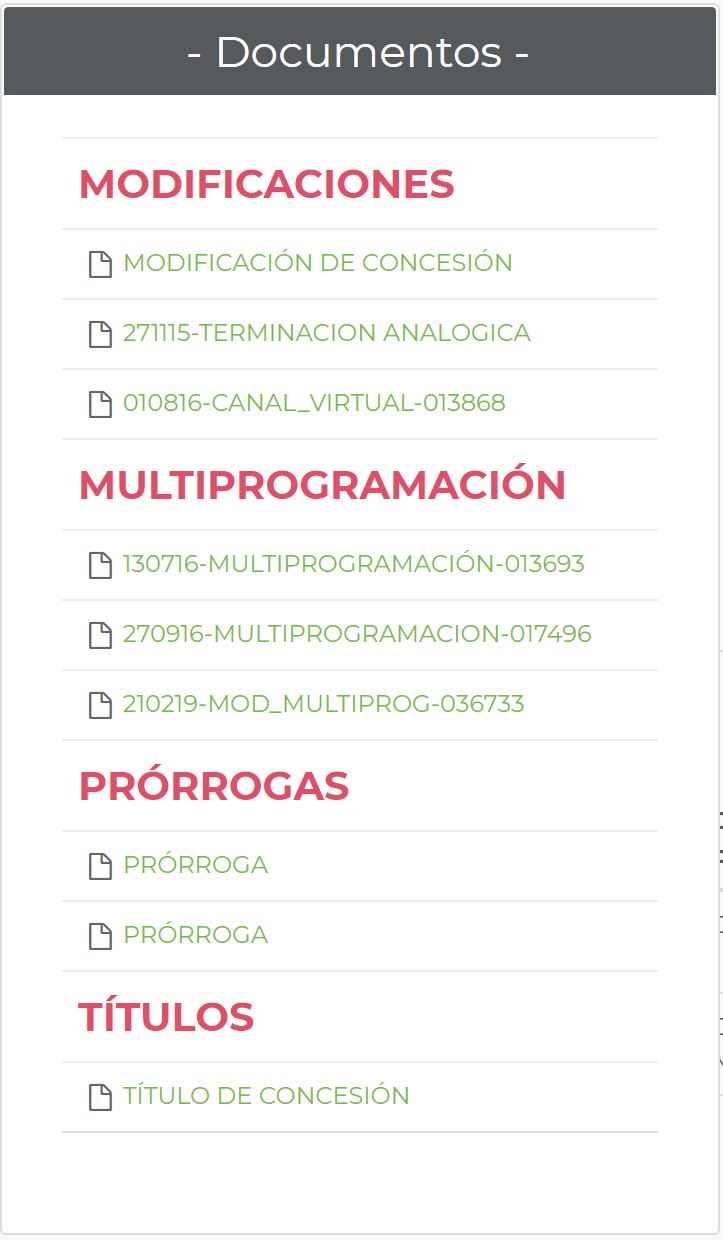
Para descargar toda la documentación de cada registro seguiremos los siguientes pasos:
- Ingresar al Excel y obtiener el folio electrónico;
- Identifica todos los PDFs de la sección de "Documentos";
- Crea una carpeta para depositar los archivos PDFs con nombre: "Numero-referencia_Distintivo-de-llamada";
- Revisa que el link del PDF no este roto;
- Descarga los documentos y los renombra de la forma "Tipo___Nombre-en-tabla-documentos___nombre-del-pdf".
A continuación el código comentado:
import wget
import requests
import xlrd
import re
import os
from bs4 import BeautifulSoup
infra_TDT_nombre = 'InfraestructuraEstacionesRadio_TV_19112019.xlsx'
infra_TDT = f'http://ucsweb.ift.org.mx/vrpc/assets/publish/infraestructura/{infra_TDT_nombre}'
url_e_folio = 'http://ucsweb.ift.org.mx/vrpc/RpcSearchController/showConcesionInfo?idConcesion='
wget.download(infra_TDT)
print('\nArchivo descargado')
folios_electronicos = []
############################################# PASO 1 #############################################
with xlrd.open_workbook(infra_TDT_nombre) as book:
first_sheet = book.sheet_by_index(0)
for fila in range(first_sheet.nrows):
if fila > 4: # Se salta las primeras 4 renglones del excel (encabezados)
No = int(first_sheet.cell(fila, 1).value)
folio_electronico = first_sheet.cell(fila, 2).value
entidad = first_sheet.cell(fila, 4).value.encode('UTF-8').decode('UTF-8').split(',')[0].strip().replace(' ', ' ').encode('UTF-8').upper()
distintivo = first_sheet.cell(fila, 8).value.encode('UTF-8').decode('UTF-8').strip()
##################################################################################################
if folio_electronico in folios_electronicos: continue # Si ya se descargó el folio, pasa al siguiente
############################################# PASO 2 #############################################
contenido = str(requests.get(f'{url_e_folio}{folio_electronico}').text).replace('\t', '').replace('\n', '')
print(f'{url_e_folio}{folio_electronico}')
dir_archivos = f'{os.getcwd()}/{No}_{distintivo}/'
re_docs = r'<\s*div[^>]*>(.*?)<\s*\/\s*div>'
aparece = re.findall(re_docs, contenido, re.MULTILINE)
coincidencias = []
if aparece: coincidencias += [ x.group() for x in re.finditer(re_docs, contenido) ]
for coincidencia in coincidencias:
if 'Documentos' in coincidencia:
table_data = [
[(cell.text, cell.a) for cell in row("td")]
for row in BeautifulSoup(coincidencia)("tr")
]
##################################################################################################
os.mkdir(dir_archivos) # PASO 3 - Crea la carpeta de la forma "Numero-referencia_Distintivo-de-llamada"
for x in table_data:
print(str(x[0][0]))
if x[0][1]:
link_pdf = re.findall(r'href=[\'"]?([^\'" >]+)', str(x[0][1]))[0] # Obtiene el link del docuemnto PDF
nombre_pdf = link_pdf.split('/')[-1]
r = requests.get(link_pdf)
if r.status_code == 404: # PASO 4 - Identifica los links rotos
print(link_pdf, 'LINK ROTO')
continue
wget.download(link_pdf, dir_archivos) # PASO 5 - Descarga el docuemento
os.rename(f'{dir_archivos}{nombre_pdf}',
f'{dir_archivos}{tipo}___{x[0][0]}___{nombre_pdf}') # PASO 5 - renombra de la forma "Tipo___Nombre-en-tabla-documentos___nombre-del-pdf".
else:
tipo = str(x[0][0])
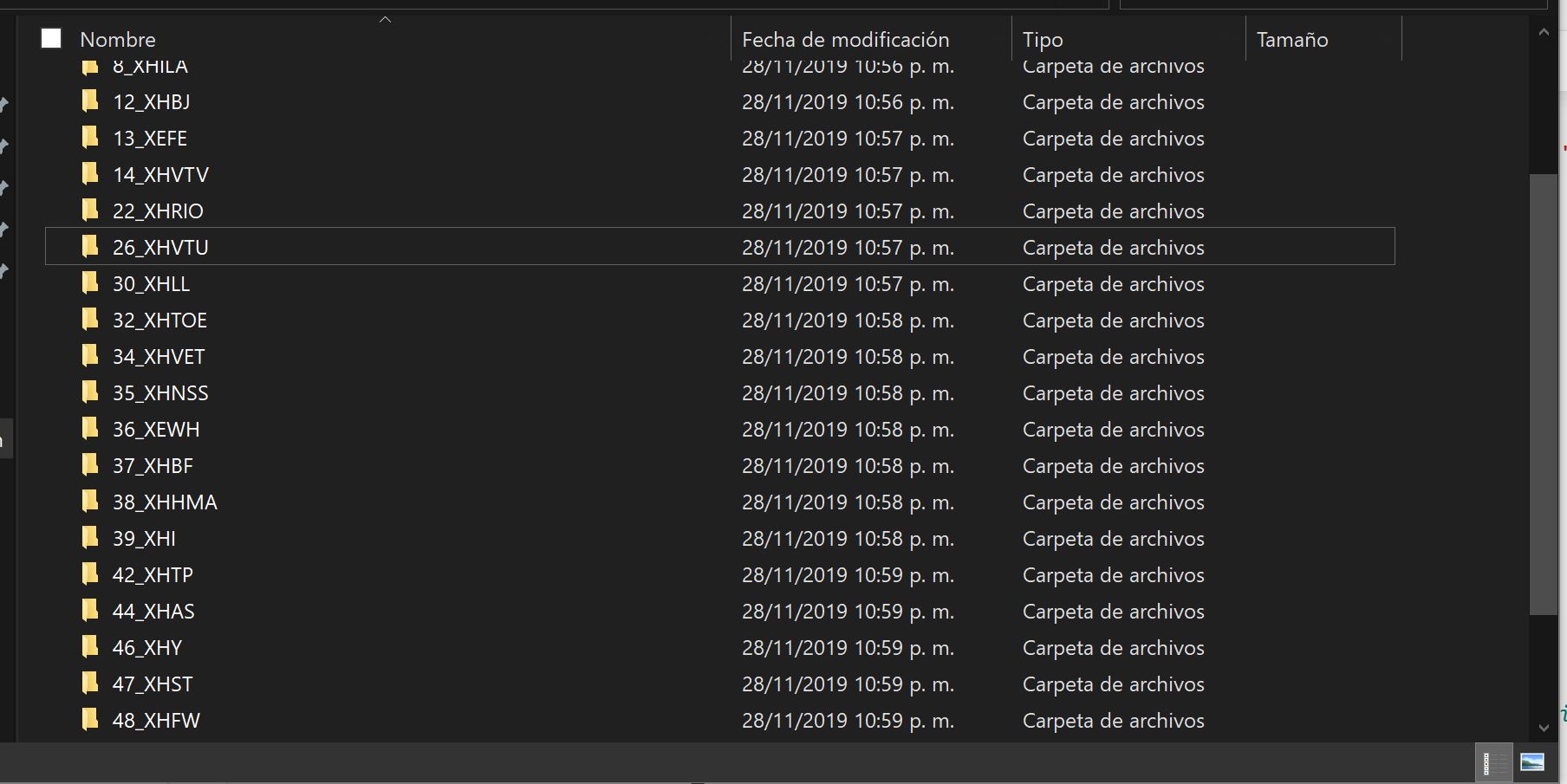
folios_electronicos.append(folio_electronico) # Para no descargar mas de una vez un Folio electrónicoAl final de ejecutar se tendra en el directorio donde se ejecuta el script una carpeta con el distintivo de llamada de la estación:
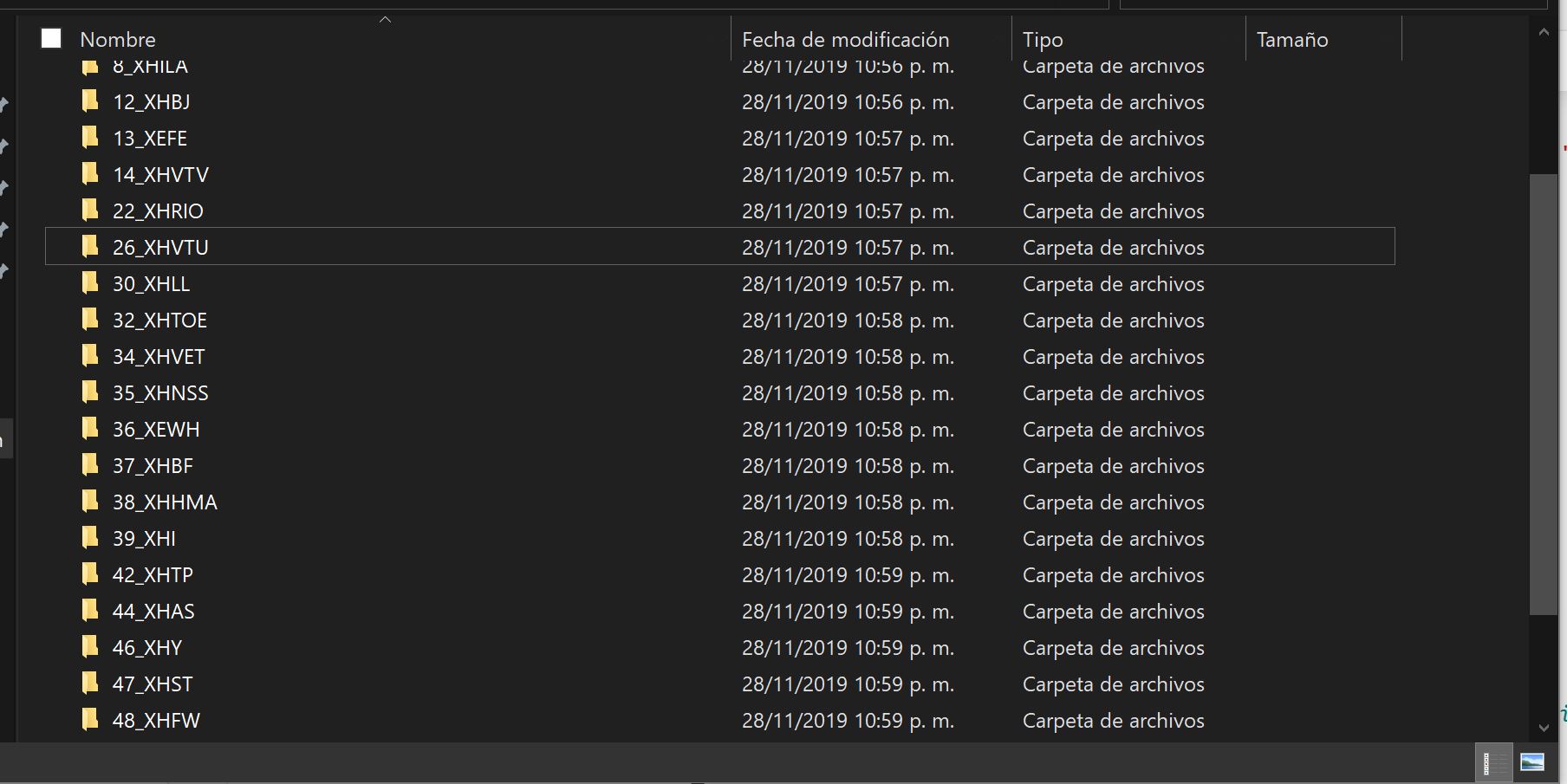
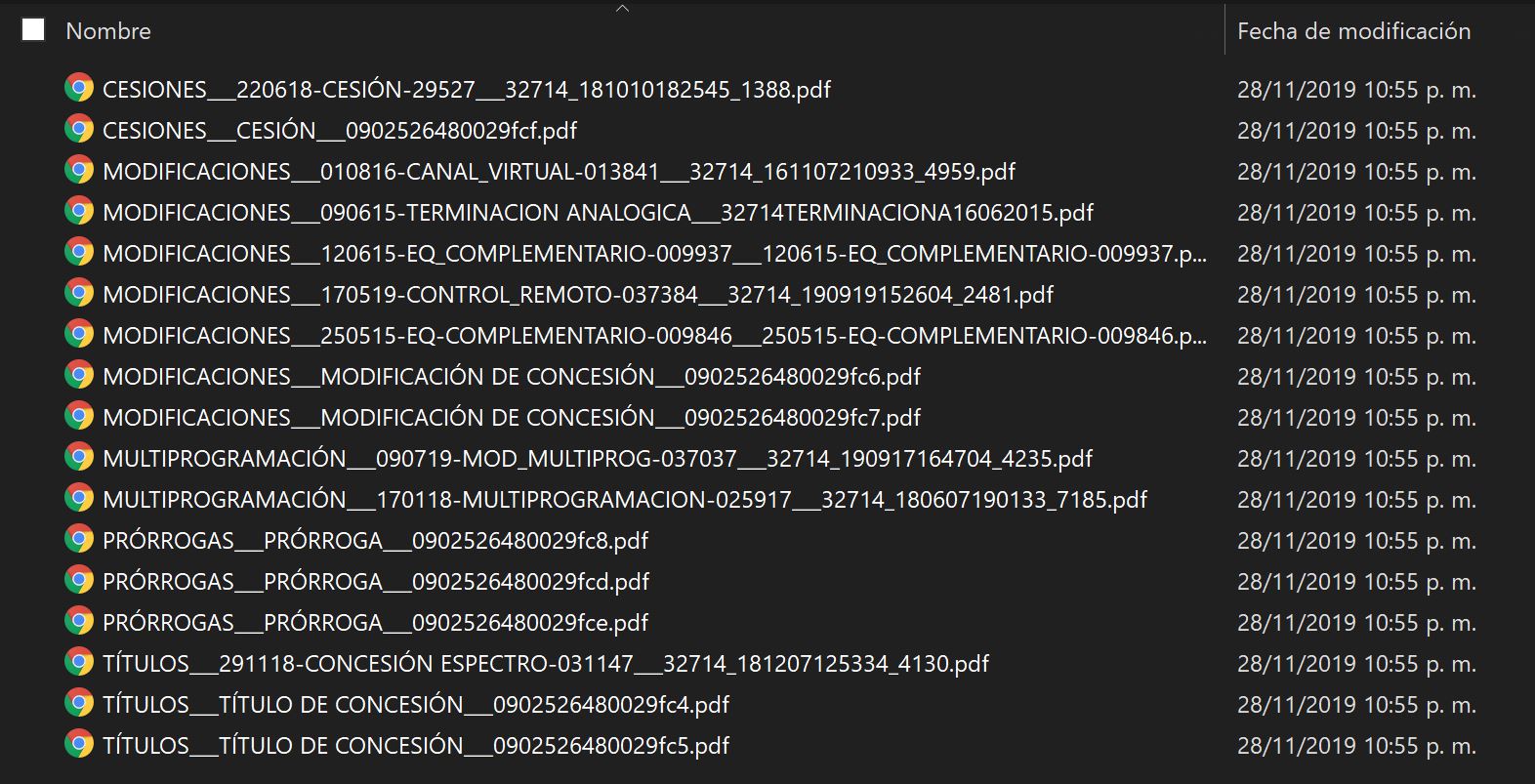
Y dentro de cada carpeta estarán contenidos la docuementación en formato PDF de cada estación de TDT del país.
Codigo sin comentarios:
import wget
import requests
import xlrd
import re
import os
from bs4 import BeautifulSoup
infra_TDT_nombre = 'InfraestructuraEstacionesRadio_TV_19112019.xlsx'
infra_TDT = f'http://ucsweb.ift.org.mx/vrpc/assets/publish/infraestructura/{infra_TDT_nombre}'
url_e_folio = 'http://ucsweb.ift.org.mx/vrpc/RpcSearchController/showConcesionInfo?idConcesion='
wget.download(infra_TDT)
print('\nArchivo descargado')
folios_electronicos = []
with xlrd.open_workbook(infra_TDT_nombre) as book:
first_sheet = book.sheet_by_index(0)
for fila in range(first_sheet.nrows):
if fila > 4: # Se salta las primeras 4 renglones del excel (encabezados)
No = int(first_sheet.cell(fila, 1).value)
folio_electronico = first_sheet.cell(fila, 2).value
entidad = first_sheet.cell(fila, 4).value.encode('UTF-8').decode('UTF-8').split(',')[0].strip().replace(' ', ' ').encode('UTF-8').upper()
distintivo = first_sheet.cell(fila, 8).value.encode('UTF-8').decode('UTF-8').strip()
if folio_electronico in folios_electronicos: continue
contenido = str(requests.get(f'{url_e_folio}{folio_electronico}').text).replace('\t', '').replace('\n', '')
print(f'{url_e_folio}{folio_electronico}')
dir_archivos = f'{os.getcwd()}/{No}_{distintivo}/'
re_docs = r'<\s*div[^>]*>(.*?)<\s*\/\s*div>'
aparece = re.findall(re_docs, contenido, re.MULTILINE)
coincidencias = []
if aparece: coincidencias += [ x.group() for x in re.finditer(re_docs, contenido) ]
for coincidencia in coincidencias:
if 'Documentos' in coincidencia:
table_data = [
[(cell.text, cell.a) for cell in row("td")]
for row in BeautifulSoup(coincidencia)("tr")
]
os.mkdir(dir_archivos)
for x in table_data:
print(str(x[0][0]))
if x[0][1]:
link_pdf = re.findall(r'href=[\'"]?([^\'" >]+)', str(x[0][1]))[0]
nombre_pdf = link_pdf.split('/')[-1]
r = requests.get(link_pdf)
if r.status_code == 404: # Identifica los links rotos
print(link_pdf, 'LINK ROTO')
continue
wget.download(link_pdf, dir_archivos)
os.rename(f'{dir_archivos}{nombre_pdf}',
f'{dir_archivos}{tipo}___{x[0][0]}___{nombre_pdf}')
else:
tipo = str(x[0][0]).encode('latin-1').decode('latin-1')
folios_electronicos.append(folio_electronico)