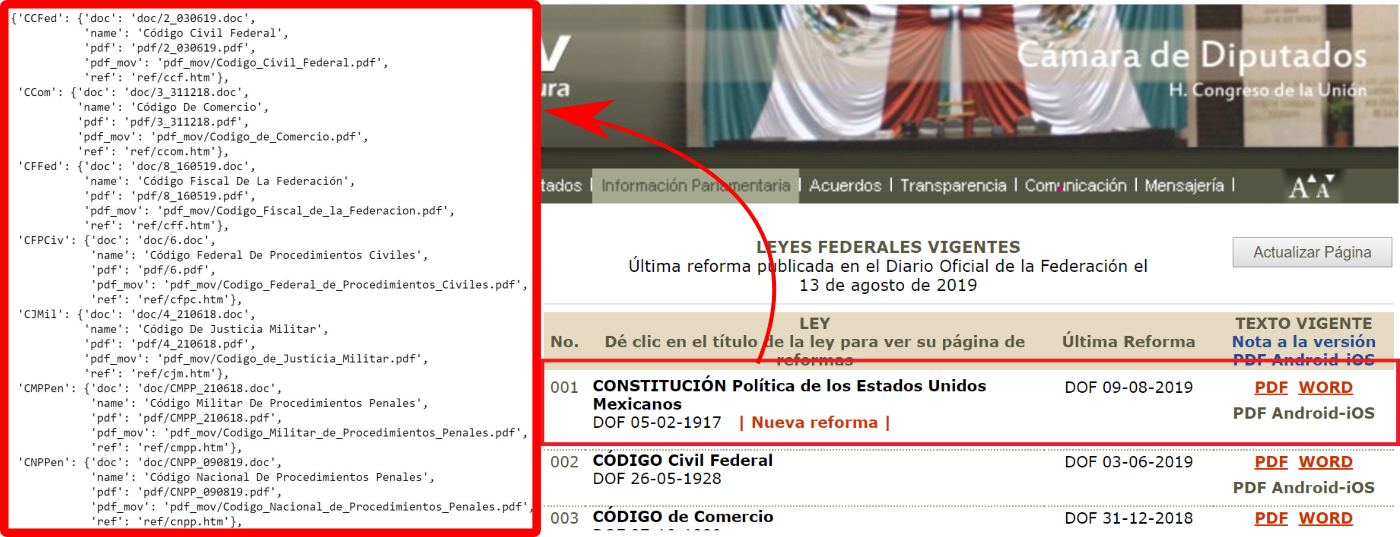
Representar todas las leyes Federales Mexicanas en una cadena JSON con python3
 mario.hernandez
22 August 2019
mario.hernandez
22 August 2019
Todas las leyes federales mexicanas se encuentra en el sitio web de la cámara de diputados: http://www.diputados.gob.mx/LeyesBiblio/index.htm, las cuales están realmente muy bien organizadas y estas se mantienen actualizadas.
No obstante lo anterior, para ciertas aplicaciones (de hecho en la mayoría de ellas) nos vemos en la necesidad de convertir la tabla HTML de la página anterior en un formato de datos que facilite el almacenamiento, mantenimiento, consulta y actualización en bases de datos. Uno de estos formatos es la notación JSON (JavaScript Object Notation), misma que obtendremos en este post.
Para comenzar, utilizaremos la librería "requests" y con su método "get" obtenemos el código HTML de la página web de la cámara de diputados que contiene todas las leyes federales, de la siguiente forma:
import requests
r = requests.get('http://www.diputados.gob.mx/LeyesBiblio/index.htm')
text = str(r.text)
print(text)Dada la gran cantidad de información, coloco sólo unas líneas del código HTML:
<html>
<style type="text/css">
A { text-decoration: none;}
A:hover { CURSOR: hand; TEXT-DECORATION: underline;}
</style>
<head>
<meta http-equiv="Content-Language" content="es-mx">
<meta http-equiv=Content-Type content="text/html; charset=windows-1252">
<title>LEYES Federales de México</title>
<script src="ima/anim_imag.js" type="text/javascript" language="JavaScript"></script>
...De este código HTML, nos interesa el que corresponde a cada uno de los renglones de la tabla que contiene listada las leyes (elementos HTML "<tr>"), por ejemplo, el primer renglón de la tabla, el cual corresponde a la Constitución Política de los Estados Unidos Mexicanos:
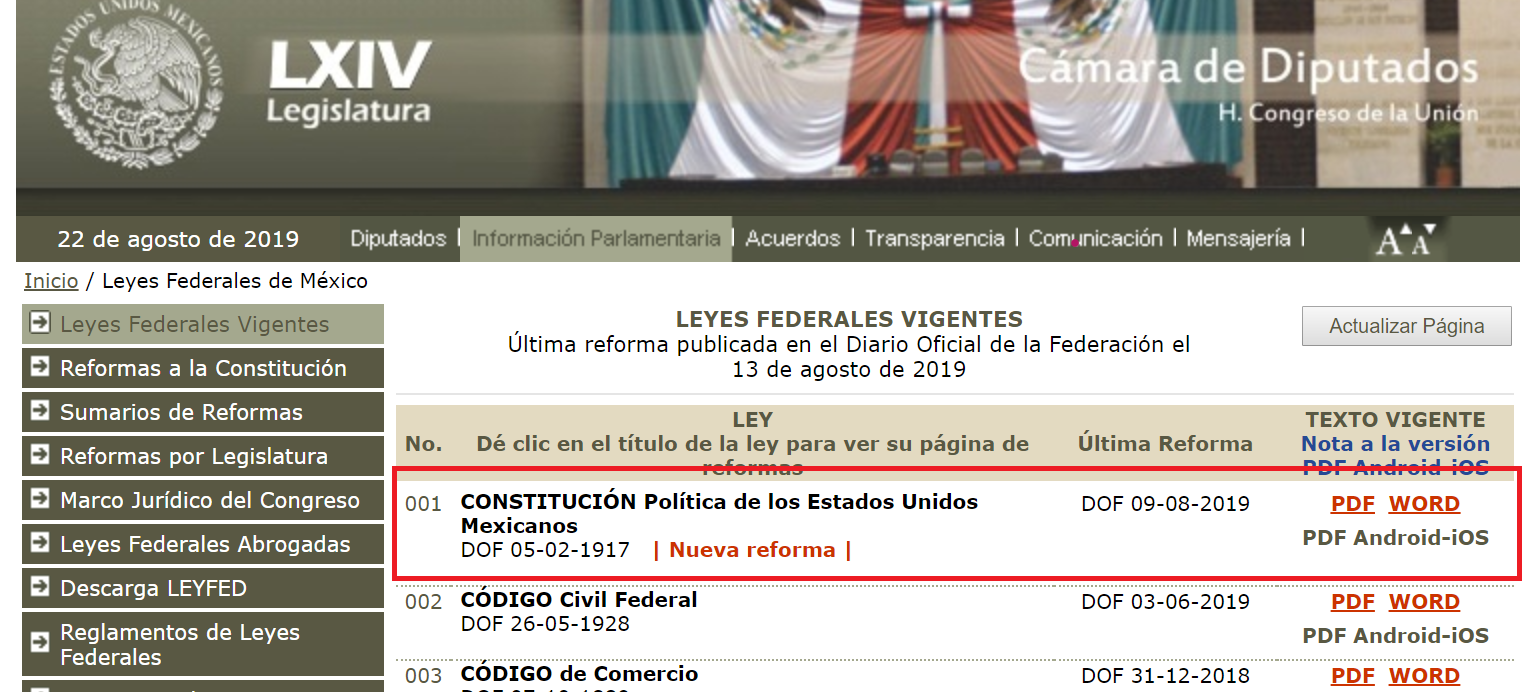
Su código HTML correspondiente es:
<tr>
<td valign="top" style="border-bottom:1px dotted #A4A88E; padding-left:3.0pt; padding-right:3.0pt; padding-top:.75pt; padding-bottom:.75pt" align="center">
<p align="center" style="text-align: center; margin: 0 0cm">
<font color="#595843" size="1"><span style="font-family:Verdana">001</span></font>
</p>
</td>
<td valign="top" style="width: 54%; border-bottom: 1px dotted #A4A88E; padding-left: 3.5pt; padding-right: 3.5pt; padding-top: 0cm; padding-bottom: 0cm">
<p class="MsoNormal" style="margin-top: 0; margin-bottom: 0"><b>
<span lang="ES-MX" style="font-family:
Verdana"><a target="_self" href="ref/cpeum.htm">
<font color="#000000" size="1">CONSTITUCIÓN Política de los Estados
Unidos Mexicanos</font></a></span></b>
</p>
<p class="MsoNormal" style="margin-top: 0; margin-bottom: 0">
<span lang="ES-MX" style="font-family:Verdana"><font size="1">DOF
05-02-1917 <font color="#CC3300"><b>| Nueva reforma |</b></font></font></span>
</p>
<p class="MsoNormal" style="margin-top: 0; margin-bottom: 0"><b>
<span lang="ES-MX" style="font-family:
Verdana"><font size="1"> </font></span></b>
</p>
</td>
<td valign="top" style="border-bottom:1px dotted #A4A88E; padding-left:3.0pt; padding-right:3.0pt; padding-top:.75pt; padding-bottom:.75pt" align="center">
<p align="center" style="margin: 0 0cm">
<span style="" lang="es-mx">
<font size="1"><span style="font-family: Verdana">
DOF 09-08-2019</span></font></span>
</p>
</td>
<td valign="top" style="border-bottom:1px dotted #A4A88E; padding-left:3.0pt; padding-right:3.0pt; padding-top:.75pt; padding-bottom:.75pt">
<p align="center" style="text-align: center; margin: 0 0cm">
<b><span lang="ES-MX" style="font-family: Verdana; text-transform: uppercase">
<font size="1" color="#CC3300">
<u><a target="_blank" href="pdf/1_090819.pdf"><font color="#CC3300">
<u>PDF</u></font></a></u> </font></span>
<span style="font-family: Verdana" bgcolor="#FFFFFF" text="#000000" link="#007777" vlink="#FF0000" alink="#008BBF" topmargin="2">
<font size="1" color="#CC3300">
<u><a target="_blank" href="doc/1_090819.doc"><font color="#CC3300">
<u>WORD</u></font></a></u></font></span></b><span bgcolor="#FFFFFF" text="#000000" link="#007777" vlink="#FF0000" alink="#008BBF" topmargin="2" style="alink: #008BBF"></span>
</p>
<p align="center" style="text-align: center; margin: 0 0cm">
<font color="#595843" style="font-size: 3pt"><b>
<span style="font-family: Verdana"> </span></b></font>
</p>
<p align="center" style="text-align: center; margin: 0 0cm">
<font size="1" color="#CC3300"><b>
<span style="font-family: Verdana"><font color="#254994">
<a target="_blank" href="pdf_mov/Constitucion_Politica.pdf">
<font color="#595843">PDF Android-iOS</font></a></font></span></b></font>
</p>
</td>
</tr>Del código HTML anterior sólo obtendremos los links a los documentos de las leyes ("PDF", "WORD" y "PDF Android-iOS"), los cuales corresponden a los elementos HTML "<a>", para lograr esto utilizaremos la Expresión regular:
regex_num = r'<\s*a[^>]*>(.*?)<\s*\/\s*a>'Para obtener una lista con todas las coincidencias de los elementos "<a>":
text = text.replace('\n','').replace('\t', '')
regex_num = r'<\s*a[^>]*>(.*?)<\s*\/\s*a>'
aparece = re.findall(regex_num, text, re.MULTILINE)
coincidencias = []
if aparece: coincidencias += [ x.group() for x in re.finditer(regex_num, text) ]Obtenemos la siguiente lista (fragmento):
[
'<a onMouseOut="MM_swapImgRestore()" onMouseOver="MM_swapImage(\'Image110\',\'\',\'ima/bt_diputados_f2.gif\',1)" target="_self" href="http://www.diputados.gob.mx"><img src="ima/bt_diputados_f1.gif" name="Image110" width="60" height="23" border="0"></a>',
'<a onMouseOut="MM_swapImgRestore()" onMouseOver="MM_swapImage(\'Image112\',\'\',\'ima/bt_info_f2.gif\',1)" target="_self" href="http://www.diputados.gob.mx/informacion_parlamentaria.htm"><img src="ima/bt_info_f2.gif" name="Image112" width="137" height="23" border="0"></a>',
'<a onMouseOut="MM_swapImgRestore()" onMouseOver="MM_swapImage(\'Image111\',\'\',\'ima/bt_acuerdos_f2.gif\',1)" target="_self" href="http://www.diputados.gob.mx/acuerdos.htm"><img src="ima/bt_acuerdos_f1.gif" name="Image111" width="60" height="23" border="0"></a>',
'<a onMouseOut="MM_swapImgRestore()" onMouseOver="MM_swapImage(\'Image113\',\'\',\'ima/bt_transp_f2.gif\',1)" target="_self" href="http://www.diputados.gob.mx/transparencia.htm"><img src="ima/bt_transp_f1.gif" name="Image113" width="82" height="23" border="0"></a>',
'<a onMouseOut="MM_swapImgRestore()" onMouseOver="MM_swapImage(\'Image114\',\'\',\'ima/bt_comunic_f2.gif\',1)" target="_self" href="http://www3.diputados.gob.mx/camara/005_comunicacion"><img src="ima/bt_comunic_f1.gif" name="Image114" width="79" height="23" border="0"></a>',
'<a href="http://201.147.98.21:81/" target="_blank" onmouseover="var img=document[\'fpAnimswapImgFP2\'];img.imgRolln=img.src;img.src=img.lowsrc?img.lowsrc:img.getAttribute?img.getAttribute(\'lowsrc\'):img.src;" onmouseout="document[\'fpAnimswapImgFP2\'].src=document[\'fpAnimswapImgFP2\'].imgRolln"><img src="ima/bt_mensaj_f1.gif" name="fpAnimswapImgFP2" width="64" height="23" border="0" id="fpAnimswapImgFP2" dynamicanimation="fpAnimswapImgFP2" lowsrc="ima/bt_mensaj_f2.gif"></a>',
'<a href="javascript:increaseFontSize();"><img src="ima/aumentar.gif" width="54" height="23" border="0" title="Agrandar Fuentes"></a>',
'<a href="javascript:decreaseFontSize();"><img src="ima/disminuir.gif" width="54" height="23" border="0" title="Disminuir Fuentes"></a>',
'<a target="_self" href="http://www.diputados.gob.mx"><font color="#595843"><u>Inicio</u></font></a>',
'<a target="_self" href="index.htm"><font color="#595843" style="font-size: 8pt">Leyes Federales Vigentes</font></a>',
'<a target="_self" href="ref/cpeum.htm"><span><font color="#FFFFFF" style="font-size: 8pt">Reformas a la Constitución</font></span></a>',
'<a target="_self" href="sumario.htm"><span style="alink: #008BBF; " bgcolor="#FFFFFF" text="#000000" link="#007777" vlink="#FF0000" topmargin="2" alink="#008BBF" ><font color="#FFFFFF" style="font-size: 8pt">Sumarios de Reformas</font></span></a>',
'<a target="_self" href="legis.htm"><font color="#FFFFFF" style="font-size: 8pt">Reformas por Legislatura</font></a>',
]Observen que se obtienen todos los elementos HTML "<a>" de la página (incluso los que se encuentran fuera de la tabla), sin embargo, solo nos interesan los que están dentro de la tabla (ya que ahí estan listadas las leyes). Existen varios formas de realizarlo, yo identificaré los elementos "<a>" que contengan las palabras "['ref/', 'pdf/', 'doc/', 'pdf_mov/']", porque son estos los que hacen referencia a los documentos ("NOMBRE DE LA LEY", "PDF", "WORD" y "PDF Android-iOS", respectivamente):
links = ['ref/', 'pdf/', 'doc/', 'pdf_mov/']
leyes_links = [ c for c in coincidencias for lnk in links if lnk in c ]Salida (fragmento):
[
'<a target="_self" href="ref/cpeum.htm"><font color="#000000" size="1">CONSTITUCIÓN Política de los Estados Unidos Mexicanos</font></a>',
'<a target="_blank" href="pdf/1_090819.pdf"><font color="#CC3300"><u>PDF</u></font></a>',
'<a target="_blank" href="doc/1_090819.doc"><font color="#CC3300"><u>WORD</u></font></a>',
'<a target="_blank" href="pdf_mov/Constitucion_Politica.pdf"><font color="#595843">PDF Android-iOS</font></a>',
'<a target="_self" href="ref/ccf.htm"><font color="#000000" size="1">CÓDIGO Civil Federal</font></a>',
'<a target="_blank" href="pdf/2_030619.pdf"><font size="1" color="#CC3300"><u>PDF</u></font></a>',
'<a href="doc/2_030619.doc"><font size="1" color="#CC3300"><u>WORD</u></font></a>',
'<a target="_blank" href="pdf_mov/Codigo_Civil_Federal.pdf"><font color="#595843">PDF Android-iOS</font></a>',
'<a href="ref/ccom.htm">CÓDIGO de Comercio</a>',
'<a target="_blank" href="pdf/3_311218.pdf"><font size="1" color="#CC3300"><u>PDF</u></font></a>',
'<a href="doc/3_311218.doc"><font size="1" color="#CC3300"><u>WORD</u></font></a>',
'<a target="_blank" href="pdf_mov/Codigo_de_Comercio.pdf"><font color="#595843">PDF Android-iOS</font></a>',
]Vean que la primera línea corresponde al nombre de la ley, seguido por los links a sus documentos "PDF", "WORD" y "PDF Android-iOS" y así sucesivamente para todas las leyes federales. Para convertir esta lista en formato JSON (o "diccionario" en python):
import re
leyes_federales = {}
articulos = ['en', 'y', 'lo', 'los', 'la', 'las',
'por', 'para', 'se', 'o', 'a', 'de',
'del', 'que', 'el', 'al', 'su']
docs = ['htm', 'pdf', 'doc', 'pdf']
for il in leyes_links:
for lnk, doc in zip(links, docs):
name_link = re.findall(f'href="({lnk}.*{doc})"\>', il)
if doc == 'htm' and name_link:
regex_num = r'>([^<>]*)<'
aparece = re.findall(regex_num, il)
coincidencias = []
if aparece: coincidencias += [ x.group()[1:-1] for x in re.finditer(regex_num, il) ]
name_ley = ''.join(coincidencias).title()
name_ley = name_ley.replace(';', '').replace('&Nbsp', ' ').replace(' ', ' ').strip()
nl = name_ley.split('(')[0].split(',')[0].split()
iniciales = [ palabra[0] for palabra in nl[:-1] if palabra.lower() not in articulos ]
iniciales = ''.join(iniciales) + nl[-1][:3]
leyes_federales[iniciales] = {}
leyes_federales[iniciales]["name"] = name_ley.replace('(', '\(').replace(')', '\)')
if name_link: leyes_federales[iniciales][lnk[:-1]] = name_link[0]Salida (Fragmento):
{
'CCFed':{
'doc':'doc/2_030619.doc',
'name':'Código Civil Federal',
'pdf':'pdf/2_030619.pdf',
'pdf_mov':'pdf_mov/Codigo_Civil_Federal.pdf',
'ref':'ref/ccf.htm'
},
'CCom':{
'doc':'doc/3_311218.doc',
'name':'Código De Comercio',
'pdf':'pdf/3_311218.pdf',
'pdf_mov':'pdf_mov/Codigo_de_Comercio.pdf',
'ref':'ref/ccom.htm'
},
'CFFed':{
'doc':'doc/8_160519.doc',
'name':'Código Fiscal De La Federación',
'pdf':'pdf/8_160519.pdf',
'pdf_mov':'pdf_mov/Codigo_Fiscal_de_la_Federacion.pdf',
'ref':'ref/cff.htm'
},
'CFPCiv':{
'doc':'doc/6.doc',
'name':'Código Federal De Procedimientos Civiles',
'pdf':'pdf/6.pdf',
'pdf_mov':'pdf_mov/Codigo_Federal_de_Procedimientos_Civiles.pdf',
'ref':'ref/cfpc.htm'
},
'CJMil':{
'doc':'doc/4_210618.doc',
'name':'Código De Justicia Militar',
'pdf':'pdf/4_210618.pdf',
'pdf_mov':'pdf_mov/Codigo_de_Justicia_Militar.pdf',
'ref':'ref/cjm.htm'
},
}Para definir las llaves de los datos en formato JSON he utilizado las iniciales de cada ley y las primeras 3 letras de la última palabra, excluyendo los artículos.
La forma de consultar los links correspondientes a las diversas leyes federales, se utilizará las llaves anteriores. Por ejemplo, para consultar la Constitución Política de los Estados Unidos Mexicanos sería mediante la llave "CPEUMex"; Para la Ley de Amparo, su llave sería "LAmp"; La Ley Federal de Telecomunicaciones y Radiodifusión, la llave es "LFTRad":
pprint.pprint(leyes_federales['CPEUMex'])
pprint.pprint(leyes_federales['LAmp'])Salida:
{
'doc': 'doc/1_090819.doc',
'name': 'Constitución Política De Los Estados Unidos Mexicanos',
'pdf': 'pdf/1_090819.pdf',
'pdf_mov': 'pdf_mov/Constitucion_Politica.pdf',
'ref': 'ref/cpeum.htm'
}
{
'doc': 'doc/LAmp_150618.doc',
'name': 'Ley De Amparo, Reglamentaria De Los Artículos 103 Y 107 De La '
'Constitución Política De Los Estados Unidos Mexicanos',
'pdf': 'pdf/LAmp_150618.pdf',
'pdf_mov': 'pdf_mov/Ley_de_Amparo_Reglamentaria-Articulos_103_y_107.pdf',
'ref': 'ref/lamp.htm'
}
Si quieres aprender python3, te recomiendo este libro Learning Python: Powerful Object-Oriented Programming.
Script completo en python3:
import requests
import re
import pprint
r = requests.get('http://www.diputados.gob.mx/LeyesBiblio/index.htm')
text = str(r.text)
text = text.replace('\n','').replace('\t', '')
leyes_federales = {}
regex_num = r'<\s*a[^>]*>(.*?)<\s*\/\s*a>'
aparece = re.findall(regex_num, text, re.MULTILINE)
coincidencias = []
if aparece: coincidencias += [ x.group() for x in re.finditer(regex_num, text) ]
articulos = ['en', 'y', 'lo', 'los', 'la', 'las',
'por', 'para', 'se', 'o', 'a', 'de',
'del', 'que', 'el', 'al', 'su']
links = ['ref/', 'pdf/', 'doc/', 'pdf_mov/']
leyes_links = [ c for c in coincidencias for lnk in links
if lnk in c ]
docs = ['htm', 'pdf', 'doc', 'pdf']
for il in leyes_links:
for lnk, doc in zip(links, docs):
name_link = re.findall(f'href="({lnk}.*{doc})"\>', il)
if doc == 'htm' and name_link:
regex_num = r'>([^<>]*)<'
aparece = re.findall(regex_num, il)
coincidencias = []
if aparece: coincidencias += [ x.group()[1:-1] for x in re.finditer(regex_num, il) ]
name_ley = ''.join(coincidencias).title()
name_ley = name_ley.replace(';', '').replace('&Nbsp', ' ').replace(' ', ' ').strip()
nl = name_ley.split('(')[0].split(',')[0].split()
iniciales = [ palabra[0] for palabra in nl[:-1] if palabra.lower() not in articulos ]
iniciales = ''.join(iniciales) + nl[-1][:3]
leyes_federales[iniciales] = {}
leyes_federales[iniciales]["name"] = name_ley.replace('(', '\(').replace(')', '\)')
if name_link: leyes_federales[iniciales][lnk[:-1]] = name_link[0]
pprint.pprint(leyes_federales)